Access local Ollama models from a cloud Kubernetes Cluster

Alex Ellis
Renting a GPU in the cloud, especially with a bare-metal host can be expensive, and even if the hourly rate looks reasonable, over the course of a year, it can really add up. Many of us have a server or workstation at home with a GPU that can be used for serving models with an open source project like Ollama.
We can combine a cloud-hosted, low cost, elastic Kubernetes cluster with a local single-node K3s cluster with a GPU, and in that way get the best of both worlds.
One option may be to try and join the node on your home network as a worker in the cloud-hosted cluster, but I don’t think that makes sense:
Why you shouldn’t use a VPN to join local hosts to your cloud Kubernetes cluster
- Kubernetes is designed for homogenous networking, where latency to each host is low and predictable, it is not built to work over WANs
- Every time the API is accessed, or the scheduler is used, it is going to have to reach out to your home network over the Internet which will introduce unreasonable latency
- A large amount of bandwidth is required between nodes, this has to go over the Internet which counts as egress traffic, and is billable
- The node in your home gets completely exposed to the cloud-based cluster, there is no security boundary or granularity
- You’ll need complex scheduling YAML including taints, tolerations and affinity rules to ensure that the node in your home and the ones in the cloud get the right workloads
So whilst it might look cool to run “kubectl get nodes” and see one that’s in your home, and a bunch that are on the cloud, there are more reasons against it than for it.
Nothing to see here. Only 65GB of bandwidth consumption from an idle k3s cluster running embedded etcd.
— Alex Ellis (@alexellisuk) October 21, 2022
Anyone else noticed similar? pic.twitter.com/Q4BVIIHJ7n
So how is inlets different?
Inlets is well known for exposing local HTTP and TCP services on the Internet, but it can also be used for private tunnels.
- There will be minimal bandwidth used, as the model is accessed over the tunnel
- The risk to your home network is minimal, as only the specific port and endpoint will be accessible remotely
- It’s trivial to access the tunneled service as a HTTP endpoint with a normal ClusterIP
So rather than having to enroll machines in your local or home network to be fully part of a cloud-hosted cluster, you only tunnel what you need. It saves on bandwidth, tightens up security, and is much easier to manage.
And what if ollama isn’t suitable for your use-case? You can use the same technique by creating your own REST API with Flask, FastAPI, Express.js, Go, etc, and expose that over the tunnel instead.
There are common patterns for accessing remote APIs in different networks such as using queues or a REST API, however building heterogeneous clusters with high latency is not one of those.
If you need more dynamic workloads and don’t want to build your own REST API to manage Kubernetes workloads, then consider the OpenFaaS project provides a HTTP API and built-in asynchronous queue system that can be used to run batch jobs and long-running tasks, it can also package Ollama as a function, and is easy to use over a HTTP tunnel. For example: How to transcribe audio with OpenAI Whisper and OpenFaaS or Stream OpenAI responses from functions using Server Sent Events.
A quick look at the setup
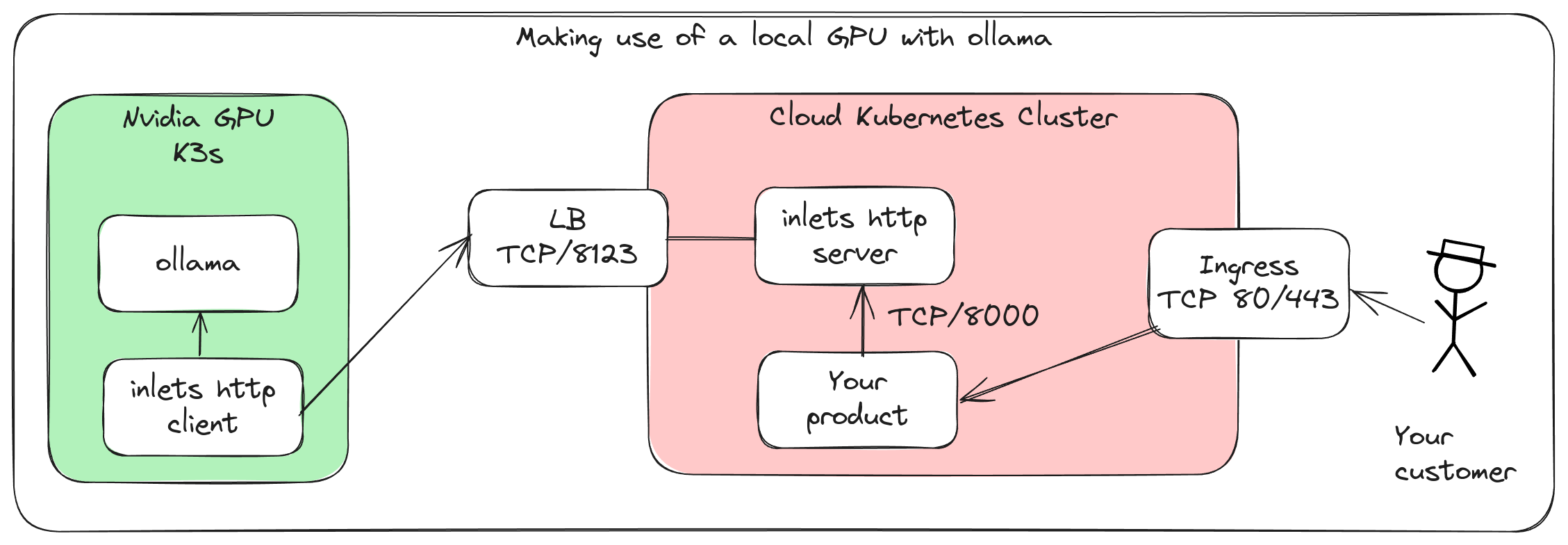
The setup with two independent Kubernetes clusters, one running locally with a GPU and ollama, the other in the cloud running your product and making HTTP requests over the tunnel.
You’ll need to do the following:
-
Setup a local machine where you’ve installed K3s, and setup nvidia-containerd.
-
Create a Kubernetes cluster using a managed Kubernetes service like DigitalOcean, AWS, or Google Cloud, or you can setup a self-hosted cluster using a tool like K3sup on a set of VMs.
-
Package and deploy Ollama along with a model as a container image, then deploy it to your local K3s cluster
-
Create a HTTPS tunnel server using inlets on the public Kubernetes cluster
-
Create a HTTPS tunnel client using inlets on the local K3s cluster
-
Finally, we will launch
curlin a Pod in the public cluster and invoke the model served by Ollama over the tunnel
Then it’ll be over to you to integrate the model into your applications, or to develop your own UI or API to expose to your users.
1. Setup a local machine with K3s and nvidia-containerd
Over on the OpenFaaS blog under the heading “Prepare a k3s with NVIDIA container runtime support”, you’ll find full instructions for setting up a single-node K3s cluster on a machine with an Nvidia GPU.
If you do not have an Nvidia GPU available, or perhaps just want to try out the tunnelling example without a K3s cluster, you can create a local cluster inside Docker using Kubernetes in Docker (KinD) or Minikube.
For example:
kind create cluster --name ollama-local
To connect to the two clusters use the: kubectl config use-context command, or the popular helper kubectx NAME available via arkade with arkade get kubectx.
2. Create a cloud-hosted Kubernetes cluster
This step is self-explanatory, for ease of use, you can setup a cloud-hosted Kubernetes cluster using a managed Kubernetes service like DigitalOcean, AWS, or Google Cloud. With a managed Kubernetes offering, load-balancers, storage, networking, and updates are managed by someone else, so it’s a good way to get started.
If you already have a self-hosted cluster on a set of VMs, or want to manage Kubernetes yourself, then K3sup provides a quick and easy way to create a highly-available cluster.
3. Package and deploy Ollama
Ollama is a wrapper that can be used to serve a REST API for interference on various machine learning models. You can package and deploy Ollama along with a model as a container image, then deploy it to your local K3s cluster.
Here’s an example Dockerfile for packaging Ollama:
FROM ollama/ollama:latest
RUN apt update && apt install -yq curl
RUN mkdir -p /app/models
RUN ollama serve & sleep 2 && curl -i http://127.0.0.1:11434 ollama pull phi3
EXPOSE 11434
Two other options for making the model available to Ollama are:
- If you do not wish to package the model into a container image and push it into a remote registry, you can use an init container, or a start-up script as the entrypoint and perform that operation at runtime.
- Another option is to download the model locally, then to copy it into a volume within the local Kubernetes cluster, then you can mount that volume into the Ollama container.
Build the image and publish it:
export OWNER="docker.io/alexellis2"
docker build -t $OWNER/ollama-phi3:0.1.0 .
docker push $OWNER/ollama-phi3:0.1.0
Now write a Kubernetes Deployment manifest and accompanying Service for Ollama:
export OWNER="docker.io/alexellis2"
cat <<EOF > ollama-phi3.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ollama-phi3
spec:
replicas: 1
selector:
matchLabels:
app: ollama-phi3
template:
metadata:
labels:
app: ollama-phi3
spec:
containers:
- name: ollama-phi3
image: $OWNER/ollama-phi3:0.1.0
ports:
- containerPort: 11434
command: ["ollama", "serve"]
---
apiVersion: v1
kind: Service
metadata:
name: ollama-phi3
spec:
selector:
app: ollama-phi3
ports:
- protocol: TCP
port: 11434
targetPort: 11434
EOF
The above is designed to work with a CPU, and can be extended to support a GPU by adding the necessary device and runtime class.
Deploy the manifest to your local K3s cluster:
kubectl apply -f ollama-phi3.yaml
You can check to see when the Pod has been downloaded and started:
kubectl get deploy/ollama-phi3 -o wide --watch
kubectl logs deploy/ollama-phi3
Check that you can invoke the model from within your local cluster.
Run an Alpine Pod, install curl and jq, then try accessing the Ollama API to see if it’s up:
kubectl run -it --rm --restart=Never --image=alpine:latest ollama-phi3-test -- /bin/sh
# apk add --no-cache curl jq
# curl -i http://ollama-phi3:11434/
Ollama is running
Next, try an inference:
# curl http://ollama-phi3:11434/api/generate -d '{
"model": "phi3",
"stream": true,
"prompt":"What is the advantage of tunnelling a single TCP host over exposing your whole local network to an Internet-connected Kubernetes cluster?"
}' | jq
The above configuration may be running on CPU, in which case you will need to wait a few seconds whilst the model runs the query. It took 29 seconds to get a response on my machine, when you have the GPU enabled, the response time will be much faster.
If you’d like to get a streaming response, and see data as it comes in, you can set stream to true in the request, and remove | jq from the command.
4. Create a HTTPS tunnel server using inlets
Now you can generate an access token for inlets, and then deploy the inlets server to your cloud-hosted Kubernetes cluster.
The inlets control-plane needs to be available on the Internet, you can do this via a LoadBalancer or through Kubernetes Ingress.
I’ll show you how to use a LoadBalancer, because it’s a bit more concise:
On the public cluster, provision a LoadBalancer service along with a ClusterIP for the data-plane.
The control-plane will be used by the tunnel client in the local cluster, and the data-plane will only be available within the remote cluster.
cat <<EOF > ollama-tunnel-server-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
name: ollama-tunnel-server-control
spec:
type: LoadBalancer
ports:
- port: 8123
targetPort: 8123
selector:
app: ollama-tunnel-server
---
apiVersion: v1
kind: Service
metadata:
name: ollama-tunnel-server-data
spec:
type: ClusterIP
ports:
- port: 8000
targetPort: 8000
selector:
app: ollama-tunnel-server
---
EOF
Apply the manifest on the remote cluster: kubectl apply -f ollama-tunnel-server-svc.yaml
Now, obtain the public IP address of the LoadBalancer by monitoring the EXTERNAL-IP field with the kubectl get svc -w -o wide ollama-tunnel-server-control command.
$ kubectl get svc -w
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.245.0.1 <none> 443/TCP 12m
ollama-tunnel-server LoadBalancer 10.245.26.4 <pending> 8123:32458/TCP 8s
ollama-tunnel-server LoadBalancer 10.245.26.4 157.245.29.186 8123:32458/TCP 2m30s
Now input the value into the following command run on your workstation:
export EXTERNAL_IP="157.245.29.186"
export TOKEN=$(openssl rand -base64 32)
echo $TOKEN > inlets-token.txt
inlets-pro http server \
--generate k8s_yaml \
--generate-name ollama-tunnel-server \
--generate-version 0.9.33 \
--auto-tls \
--auto-tls-san $EXTERNAL_IP \
--token $TOKEN > ollama-tunnel-server-deploy.yaml
Apply the generated manifest to the remote cluster:
kubectl apply -f ollama-tunnel-server-deploy.yaml
You can check that the tunnel server has started up properly with:
kubectl logs deploy/ollama-tunnel-server
At this stage, you should have the following on your public cluster:
$ kubectl get service,deploy
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.245.0.1 <none> 443/TCP 110m
service/ollama-tunnel-server-control LoadBalancer 10.245.7.92 157.245.29.186 8123:31581/TCP 76m
service/ollama-tunnel-server-data ClusterIP 10.245.40.138 <none> 8000/TCP 76m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ollama-tunnel-server 1/1 1 1 88m
5. Create a HTTPS tunnel client using inlets
Now you can create a tunnel client on your local K3s cluster:
export EXTERNAL_IP=""
inlets-pro http client \
--generate k8s_yaml \
--generate-name ollama-tunnel-client \
--url "wss://$EXTERNAL_IP:8123" \
--token-file inlets-token.txt \
--upstream=http://ollama-phi3:11434 \
> ollama-tunnel-client-deploy.yaml
The upstream uses the ClusterIP of the Ollama service within the local cluster, where the port is 11434.
The above will generate three Kubernetes objects:
- A Deployment for the inlets client
- A Secret for the control-plane token
- A Secret for your license key for inlets
Apply the generated manifest to the local cluster:
kubectl apply -f ollama-tunnel-client-deploy.yaml
Check that the tunnel was able to connect:
kubectl logs deploy/ollama-tunnel-client
inlets-pro HTTP client. Version: 0.9.32
Copyright OpenFaaS Ltd 2024.
2024/08/09 11:49:02 Licensed to: alex <alex@openfaas.com>, expires: 47 day(s)
Upstream: => http://ollama-phi3:11434
time="2024/08/09 11:49:02" level=info msg="Connecting to proxy" url="wss://157.245.29.186:8123/connect"
time="2024/08/09 11:49:03" level=info msg="Connection established" client_id=91612bca9c0f41c4a313424db9b6a0c7
There will be no way to access the tunneled Ollama service from the Internet, this is by design, only the control-plane is made available to the client on port 8123.
Your local Kubernetes cluster should have the following:
$ kubectl get svc,deploy
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 110m
service/ollama-phi3 ClusterIP 10.96.128.9 <none> 11434/TCP 106m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ollama-phi3 1/1 1 1 106m
deployment.apps/ollama-tunnel-client 1/1 1 1 83m
6. Invoke the model from the public cluster
Switch back to the Kubernetes cluster on the public cloud.
Now you can run a Pod in the public cluster and invoke the model served by Ollama over the tunnel:
kubectl run -it --rm --restart=Never --image=alpine:latest ollama-phi3-test -- /bin/sh
# apk add --no-cache curl
# curl -i http://ollama-tunnel-server-data:8000/api/generate -d '{
"model": "phi3",
"stream": true,
"prompt":"How can you combine two networks?"
}'
Example response:
HTTP/1.1 200 OK
Content-Type: application/x-ndjson
Date: Fri, 09 Aug 2024 11:56:19 GMT
Transfer-Encoding: chunked
{"model":"phi3","created_at":"2024-08-09T11:56:19.486043693Z","response":"Com","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:19.543130824Z","response":"bin","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:19.598975314Z","response":"ing","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:19.654731638Z","response":" two","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:19.710487681Z","response":" or","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:19.766891184Z","response":" more","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:19.822626098Z","response":" neural","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:19.880506452Z","response":" networks","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:19.937516988Z","response":" is","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:19.993925621Z","response":" a","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:20.049548473Z","response":" technique","done":false}
{"model":"phi3","created_at":"2024-08-09T11:56:20.106052896Z","response":" commonly","done":false}
Note in this case, the service name for the tunnel is used, along with the default HTTP port for an inlets tunnel which is 8000, instead of the port 11434 that Ollama is listening in the local cluster.
Anything you deploy within your public Kubernetes cluster can access the model served by Ollama, by making HTTP requests to the data plane of the tunnel server with the address: http://ollama-tunnel-server-data:8000.
See also: Ollama REST API
Conclusion
In this post, you learned how to use a private tunnel to make a local GPU-enabled HTTP service like Ollama available in a remote Kubernetes cluster. This can be useful for serving models from a local GPU, or for exposing a service that is not yet ready for the public Internet.
You can now integrate the model into your applications, or develop your own UI or API to expose to your users using the ClusterIP of the data-plane service.
We exposed the control-plane for the tunnel server over a cloud Load Balancer, however if you have multiple tunnels, you can use a Kubernetes Ingress Controller instead, and direct traffic to the correct tunnel based on the hostname and an Ingress record. If you take this route, just remove the --auto-tls-san flags from the inlets-pro command as they will no longer be needed. You can use cert-manager to terminate TLS instead.
If you’d like to see a live demo, watch the video below:
If you enjoyed this post, you can find similar examples in the inlets docs, or on the inlets blog.
You may also like:
Subscribe for updates and new content from OpenFaaS Ltd.
By providing your email, you agree to receive marketing emails.